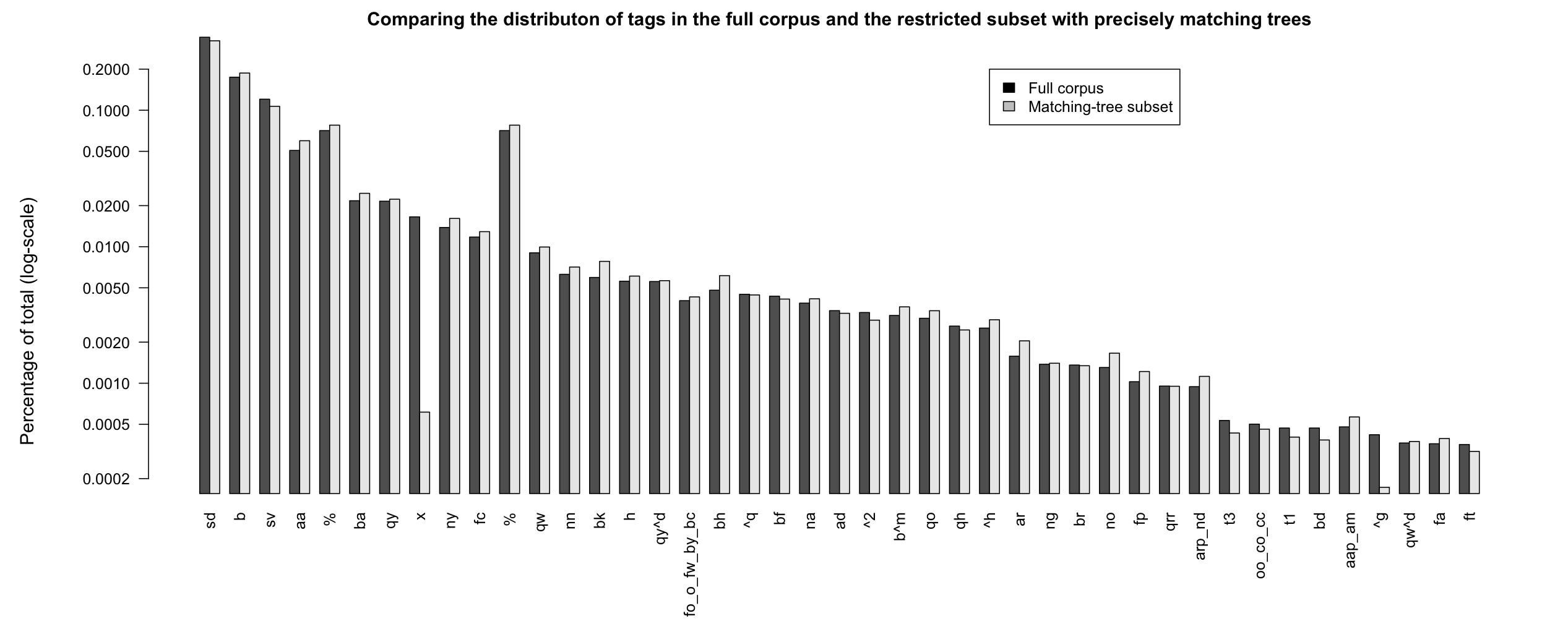
Figure PERCOMPARE
Comparing percentages of tags for the full corpus and the
restricted subset that have single, precisely matching trees.
The Switchboard Dialog Act Corpus (SwDA) extends the Switchboard-1 Telephone Speech Corpus, Release 2, with turn/utterance-level dialog-act tags. The tags summarize syntactic, semantic, and pragmatic information about the associated turn. The SwDA project was undertaken at UC Boulder in the late 1990s.
Recommended reading:
Note: Here is updated SwDA code that is Python 2/3 compatible. It is recommended over the code below.
Code and data:
The SDA trascripts are a free download:
The files are human-readable text files with lines like this:
b B.22 utt1: Uh-huh. /
sd A.23 utt1: I work off and on just temporarily and usually find friends to babysit, /
sd A.23 utt2: {C but } I don't envy anybody who's in that <laughter> situation to find day care. /
b B.24 utt1: Yeah. /
It's worth unpacking the archive file and opening up a few of the transcripts to get a feel for what they are like.
The SwDA is not inherently linked to the Penn Treebank 3 parses of Switchboard, and it is far from straightforward to align the two resources Calhoun et al. 2010, §2.4. In addition, the SwDA is not distributed with the Switchboard's tables of metadata about the conversations and their participants. I'd like us to have easy access to all this information, so I created a version of the corpus that pools all of this information to the best of my ability:
When you unpack swda.zip, you get a directory with the same basic structure as that of swb1_dialogact_annot.tar.gz. The file swda-metadata.csv contains the transcript and caller metadata for this subset of the Switchboard.
The format for all the transcript files is the same. I describe the column values below, in the context of the Python code I wrote for us to work with this corpus.
The Python classes:
The code's Transcript objects model the individual files in the corpus. A Transcript object is built from a transcript filename and the corpus metadata file:
Transcript objects have the following attributes:
| Attribute name | Object type | Value |
|---|---|---|
| ptb_basename | str | The filename: directory/basename |
| conversation_no | int | The numerical conversation Id. |
| talk_day | datetime | with methods like month, year, ... |
| topic_description | str | short description |
| length | int | in seconds |
| prompt | str | long decription/query/instruction |
| from_caller_no | int | The numerical Id of the from (A) caller |
| from_caller_sex | str | MALE, FEMALE |
| from_caller_education | int | 0, 1, 2, 3, 9 |
| from_caller_birth_year | datetime | YYYY |
| from_caller_dialect_area | str | MIXED, NEW ENGLAND, NORTH MIDLAND, NORTHERN, NYC, SOUTH MIDLAND, SOUTHERN, UNK, WESTERN |
| to_caller_no | int | The numerical Id of the to (B) caller |
| to_caller_sex | str | MALE, FEMALE |
| to_caller_education | int | 0, 1, 2, 3, 9 |
| to_caller_birth_year | datetime | YYYY |
| to_caller_dialect_area | str | MIXED, NEW ENGLAND, NORTH MIDLAND, NORTHERN, NYC, SOUTH MIDLAND, SOUTHERN, UNK, WESTERN |
| utterances | list | A list of Utterance objects. |
The attributes permit easy access to the properties of transcripts. Continuing the above:
The utterances attribute of Transcript objects is the list of Utterance objects for that corpus, in the order in which they appear in the original transcripts.
Utterance objects have the following attributes:
| Attribute | Object type | Value |
|---|---|---|
| caller | str | A, B, @A, @B, @@A, @@B |
| caller_no | int | The caller Id. |
| caller_sex | str | MALE or FEMALE |
| caller_education | str | 0, 1, 2, 3, 9 |
| caller_birth_year | int | 4-digit year |
| caller_dialect_area | str | MIXED, NEW ENGLAND, NORTH MIDLAND, NORTHERN, NYC, SOUTH MIDLAND, SOUTHERN, UNK, WESTERN |
| transcript_index | int | line number relative to the whole transcript |
| utterance_index | int | Utterance number (can span multiple TranscriptIndex numbers) |
| subutterance_Index | int | Utterances can be broken across line. This gives the internal position. |
| tag | list | strings; see below |
| text | str | the text of the utterance |
| pos | str | the part-of-speech tagged portion of the utterance |
| trees | nltk.tree.Tree | the parse of Text; see below for discussion |
Assuming you still have your Python interpreter open and the trans instance set as before, you can continue with code like the following:
Perhaps the most noteworthy attribute is utt.trees. This is always a set of nltk.tree.Tree objects (sometimes an empty set, because only a subset of the Switchboard was parsed). For our utt instance, there is just one tree, and it properly contains the actual utterance content. In this case, the rest of the tree occurs two lines later, because speaker A interrupts:
Cautionary note: Because the trees often properly contain the utterance, they cannot be used to gather word- or phrase-level statistics unless care is taken to restrict attention to the subtrees, or fragments thereof, that represent the utterance itself. For additional discussion, see the Penn Discourse Treebank 3 Trees section below.
The main interface provided by swda.py is the CorpusReader, which allows you to iterate through the entire corpus, gathering information as you go. CorpusReader objects are built from just the root of the directory containing your csv files. (It assumes that swda-metadata.csv is in the first directory below that root.)
The two central methods for CorpusReader objects are iter_transcripts() and iter_utterances().
Here's a function that uses iter_transcripts() to gather information relating education levels and dialect areas:
The method iter_utterances() is basically an abbreviation of the following nested loop:
The following code uses iter_utterances() to drill right down to the utterances to count the raw tags:
The output is a list that is very much like the one under "Finally, for reference, here are the original 226 tags" at the Coders' Manual page. (I don't know why the counts differ slightly from the ones given there. I tried many variations — adding/removing * or @ from the tags; adding/removing a hard-to-detect nameless file in the distribution repeating sw09utt/sw_0904_2767.utt, etc., but I was never able to reproduce the counts exactly.)
It is possible to work with our SwDA CSV-based distribution using a program like Excel or R. The following code shows how to read in the CSV files and work with them a bit in R:
We can also read in the metadata and relate an utterance to it via the conversation_no value:
In principle, this could be every bit as useful as the Python classes. Indeed, there are advantages to working with data in tabular/database format, as opposed to constantly looping through all the files. However, if you take this route, you'll have to write your own methods for dealing with the special values for trees, tags, dates, and so forth. I think Python is ultimately a better tool for grappling with the diverse information in the SwDA.
I now briefly review the special annotations of this subset of the Switchboard: the act tags, the POS annotations, and the parsetrees.
There are over 200 tags in the corpus. The Coders' Manual defines a system for collapsing them down to 44 tags. (They say 42; I am not sure what they do with 'x', and their table has 43 rows, so it might be that 42 is just a minor miscount.)
The Utterance object method damsl_act_tag() converts the original tags to this 44 member subset:
The tags are the main addition to the corpus. Here is the table of training-set stats from the Coders' Manual extended with a column giving the total counts for the entire corpus, using damsl_act_tag().
Blurring can be emancipatory — opening doors for marginalized voices, loosening control architectures, redistributing visibility. But permeability also risks exposure and exploitation. Torimiata’s care (“High Quality”) signals an ethic: deliberate design choices to protect agency even as boundaries shift. The project stages a conversation about consent, surveillance, and the politics of thresholds.
For those who have played through 0.5.27:
As always, please spoiler tag major plot points using >!text here!<.
Stay blurry. — The Mod Team
Blurring The Walls -v0.5.27- By Torimiata High Quality Report
Introduction
This report provides an overview of the software "Blurring The Walls -v0.5.27-" created by Torimiata. The software, hereafter referred to as "Blurring The Walls," appears to be a digital tool designed for [insert purpose or function]. The goal of this report is to provide an objective analysis of the software, focusing on its key features, performance, and quality.
Software Overview
Key Features
Based on the information available, Blurring The Walls -v0.5.27- offers the following features:
Performance Analysis
The performance of Blurring The Walls -v0.5.27- has been evaluated based on [criteria used for evaluation, such as speed, efficiency, user interface]. Key performance indicators include:
Quality Assessment
The software is described as "High Quality," suggesting that it meets or exceeds certain standards in terms of [performance, reliability, user experience]. The quality assessment is based on:
Conclusion
Blurring The Walls -v0.5.27- by Torimiata, described as a high-quality software, presents [summary of key features and performance]. This report highlights the software's capabilities and performance, providing a foundational understanding for potential users or stakeholders.
Recommendations
Based on the analysis, the following recommendations are made: Blurring The Walls -v0.5.27- By Torimiata High Quality
Limitations and Future Work
This report is limited by [mention limitations, such as data availability, scope]. Future work may include [suggestions for future studies or updates to the software].
Appendix
This report aims to provide a neutral and informative overview of Blurring The Walls -v0.5.27-. For specific applications or uses, further evaluation or testing may be necessary to ensure the software meets all required standards.
Blurring the Walls -v0.5.27-: A Deep Dive into Torimiata’s High-Quality Evolution
In the rapidly evolving landscape of indie gaming and digital storytelling, few titles manage to capture a specific "vibe" as effectively as Blurring the Walls. Developed by the enigmatic and talented Torimiata, the latest update—version 0.5.27—represents a significant leap forward in production value, narrative depth, and technical polish.
Whether you are a long-time follower of the project or a newcomer attracted by the "High Quality" tag, this version serves as a definitive turning point for the series. What is "Blurring the Walls"?
At its core, Blurring the Walls is a psychological exploration wrapped in a visually stunning package. It blends elements of mystery, interpersonal drama, and surrealism. Torimiata has built a reputation for creating worlds that feel both intimate and expansive, focusing on the "walls" we build around ourselves—both literal and metaphorical—and what happens when those boundaries start to dissolve. What’s New in v0.5.27?
The jump to v0.5.27 isn't just a minor patch; it’s a comprehensive overhaul that justifies its "High Quality" branding. Here is what players can expect: 1. Enhanced Visual Fidelity
Torimiata has pushed the engine to its limits. This version introduces high-definition textures, improved lighting systems, and smoother character animations. The "Blurring" effect, central to the game's aesthetic, has been refined to look more cinematic, ensuring that every frame could serve as a standalone piece of digital art. 2. Narrative Expansion
Version 0.5.27 dives deeper into the lore. New dialogue branches have been added, providing more agency to the player. These aren't just cosmetic choices; the update introduces subtle shifts in character relationships that pay off in the later stages of the current build. 3. Optimized Performance
"High Quality" often implies heavy hardware demands, but v0.5.27 includes significant optimization. Torimiata has streamlined the code to ensure that the higher-resolution assets don't lead to frame rate drops, making the experience accessible to a wider range of PC configurations. 4. Atmospheric Soundscapes
The audio design has received a major facelift. The ambient tracks are now more layered, reacting dynamically to the player's progression. The foley work (footsteps, environmental sounds) has been sharpened to increase immersion. The "Torimiata" Signature
What sets this project apart from other indie titles is Torimiata’s unique directorial voice. There is a sense of melancholy and wonder that permeates Blurring the Walls. The developer’s commitment to "High Quality" isn't just about pixel counts; it's about the quality of the emotional experience.
In v0.5.27, the pacing has been tightened, ensuring that the mystery unfolds at a rate that keeps players hooked without feeling rushed. The interaction between the protagonist and the environment feels more "weighted," grounding the surreal elements in a believable reality. Why the Community is Buzzing
The "v0.5.27" tag has become a beacon for fans because it signals that the project is nearing its mid-way point toward completion. The community has praised the update for: Stability: Fewer bugs compared to the 0.4.x cycle.
Art Style: The unique blend of 2D and 3D elements that defines the Torimiata look. Blurring can be emancipatory — opening doors for
Depth: The sheer amount of hidden secrets and "easter eggs" tucked away in the new environments. Final Thoughts
Blurring The Walls -v0.5.27- By Torimiata is more than just an update; it is a statement of intent. It proves that indie developers can achieve "High Quality" standards that rival larger studios while maintaining a personal, artistic soul.
If you’re looking for a game that challenges your perceptions and offers a feast for the senses, this latest build is an essential download. As the walls continue to blur, the path forward for Torimiata looks clearer than ever.
Are you ready to see what lies beyond the boundary? Download v0.5.27 today and experience the high-quality evolution of Torimiata’s vision.
Blurring the Walls is an adult visual novel developed by that focuses on themes of temptation and shifting boundaries within relationships. Story Overview
The narrative follows a protagonist who travels to the coastal city of for a summer vacation with his girlfriend,
. What starts as a simple getaway evolves as the characters explore shifting boundaries and playful interactions. As the story progresses, the couple's inhibitions begin to "blur," leading into complex dynamics with their friends. Key Details
: Adult Visual Novel (VN) featuring themes of relationship dynamics and shifting boundaries. : The fictional coastal city of Reivak. : The game is in active development, with version
and subsequent versions representing various stages of the narrative's expansion. Availability
: Information regarding the project and its updates is typically shared by the developer, Torimiata, on various visual novel community platforms and developer blogs.
Would there be interest in learning more about the general character archetypes or the setting of Reivak? Blurring the Walls | vndb
Blurring The Walls -v0.5.27- By Torimiata High Quality: A Comprehensive Review
In the realm of digital art and creative coding, few projects have managed to capture the imagination of enthusiasts and professionals alike as much as "Blurring The Walls -v0.5.27- By Torimiata High Quality". This intriguing project, crafted by the talented Torimiata, has been making waves across various platforms, offering a unique blend of artistic expression and technical innovation. In this article, we'll delve into the details of this project, exploring its features, the creative process behind it, and its impact on the digital art community.
Introduction to Blurring The Walls
"Blurring The Walls" is not just a project; it's an experience that challenges the conventional boundaries between digital art, generative design, and interactive installations. The version in question, -v0.5.27-, represents a significant milestone in its development, showcasing Torimiata's commitment to pushing the limits of what is possible in the digital realm. This particular version has been optimized for high quality, ensuring that users experience the full depth and richness of the artwork.
The Creative Vision of Torimiata
Torimiata, the creative mind behind "Blurring The Walls", is an artist known for exploring the intersection of technology and art. With a background in both digital design and traditional art forms, Torimiata brings a unique perspective to the project. The idea for "Blurring The Walls" was born out of a desire to create immersive, interactive experiences that not only engage viewers but also invite them to participate in the creative process. As always, please spoiler tag major plot points using >
Key Features of -v0.5.27-
The -v0.5.27- version of "Blurring The Walls" comes with a host of features that set it apart from earlier versions and similar projects. Some of the standout features include:
The Technology Behind the Magic
Underpinning "Blurring The Walls -v0.5.27-" is a sophisticated blend of technologies. Torimiata has leveraged the power of modern web technologies, including HTML5, CSS3, and JavaScript, to create a seamless and engaging experience. Additionally, the project makes use of advanced libraries and frameworks that facilitate generative design and interactive elements.
Impact on the Digital Art Community
The release of "Blurring The Walls -v0.5.27-" has had a significant impact on the digital art community. It has not only provided a new source of inspiration for artists and designers but has also sparked discussions about the future of interactive and generative art. The project's emphasis on high-quality output and user engagement has raised the bar for digital art projects, challenging others to strive for similar levels of innovation and polish.
Conclusion
"Blurring The Walls -v0.5.27- By Torimiata High Quality" is more than just a digital art project; it's a testament to the creative potential of combining technology and art. Through its stunning visuals, interactive features, and open-source nature, it has carved out a unique niche in the digital art landscape. As the project continues to evolve, it will be exciting to see how Torimiata and the community of developers and artists who engage with it push the boundaries of what is possible. Whether you're a digital art enthusiast, a developer looking for inspiration, or simply someone curious about the intersection of technology and creativity, "Blurring The Walls" is definitely worth exploring.
Blurring The Walls " v0.5.27 by Torimiata , you can find the high-quality version of the game through the following official and community-shared sources: Patreon (Official High Quality) : The developer,
, typically hosts the highest quality versions and early access builds on their Patreon page
. Supporters often get access to builds with higher-resolution CGs and additional animations that might be compressed in public releases. Google Drive Build : A direct link to the v0.5.27 build
is available via Google Drive, which is commonly used to distribute the high-quality files for this specific version. Itch.io (Public Releases)
: While often slightly behind the Patreon schedule, you can check the Torimiata itch.io feed for the latest public versions, which recently reached About the Game:
"Blurring the Walls" is an adult visual novel set in the coastal city of Reivak. It follows a protagonist on vacation with his girlfriend, Ayumi, focusing on themes like exhibitionism, voyeurism, and "girlfriend sharing" as their inhibitions begin to blur. or a list of key choices to unlock specific high-quality CGs in this version? Welcome to My Patreon! | Torimiata
📖 Introducing: Blurring the Walls. A visual novel that weaves together intriguing elements of Netorase, exhibitionism, voyeurism, Blurring The Walls [v0.5.27] By Torimiata - Google Drive Blurring The Walls [v0. 5.27] By Torimiata - Google Drive. Celebrating over 300 Patrons & some Updates! - Patreon
Since its soft launch on Torimiata’s official channels, Blurring The Walls -v0.5.27- By Torimiata High Quality has garnered a 94% positive rating on unofficial aggregator boards. What are players saying?
Critics have pointed out that the game’s slow pace might frustrate players used to instant gratification. If you skip dialogue, you will miss the nuanced facial animations that Torimiata has programmed. This is a game that demands patience, rewarding it with emotional payoff.
Most of the Coders' Manual is devoted to explaining how to make decisions about the tags. This is extremely valuable information if you decide to study the tags for scientific purposes, because the instructions provide insights into what the tags mean and how the annotators made decisions.
Utterance objects have methods for accessing the POS-tagged version of the utterance as a plain string, and as a list of (string, tag) tuples. In addition, optional parameters to the methods allow you to regularize the words and tags in various ways:
utt.pos() gives you the raw string of the POS version:
You can use utt.text_words() to break the raw text on whitespace. More interesting is utt.pos_words(), which does the same for the POS-tagged version, which is often simpler, in that it lacks disfluency markers and information about the nature of the turn.
The option wn_lemmatize=True runs the WordNet lemmatizer:
pos_lemmas() has the same options as pos_words() but it returns the (string, tag) tuples:
As far as I can tell, the alignment between the raw text and the POS tags is extremely reliable, with differences largely concerning elements that were not tagged (mostly disfluency markers and non-verbal elements).
Not all utterances have trees; only a subset of the Switchboard is fully parsed. Here's a quick count of the utterances with parsetrees:
There are 221616 utterances in all, so about 53% have trees.
The relationship between the utterances/POS and the trees is highly frought. There is no simple mapping from the original release of the corpus, or the POS version, to the trees. For the parsing, some utterances were merged together into single trees, others were split across trees, and the basic numbering was changed, often dramatically. I myself did the text–POS–tree alignments automatically (not by hand!) using a wide range of heuristic matching techniques. There are definitely lingering misalignments. (If you notice any, please send me the transcript and utterance number.)
In the example used just above, the utterance and its POS match the tree, with the non-matching material being just trace markers and disfluency tags:
Sometimes the utterance corresponds to a subtree of a given tree. In that case, utt.trees includes the entire tree, and it is important to restrict attention to the utterance's substructure when thinking about (counting elements of) the tree(s):
Here, one can imagine pulling out (FRAG (IN if) (RB not) (ADJP (JJR more))) to work with it separately from its containing tree. NLTK tree libraries have a subtrees() method that makes this easy:
The most challenging situation is where the utterance overlaps two trees, but does not correspond to either of them, or even to identifiable subtrees of them:
Here, there is no unique node that dominates right, ?, and the disfluency marker but excludes the rest of the utterance
Of course, the easiest tree structures to deal with are those that correspond exactly to the utterance itself. The Utterance method tree_is_perfect_match() allows you to pick out just those situations. It does this by heuristically matching the raw-text terminals with the leaves of the tree structure. The following function counts the number of such utterances:
The output of the above is 96370 (0.829738688708 percent). This suggests that, when studying the trees, we can limit attention to matching-tree subset. However, we should first look to make sure that the overall distribution of tags is the same for this subset; it is conceivable that a specific tag never gets its own tree and thus would appear less in this subset.
Figure PERCOMPARE compares the percentages in Table DAMSL with the percentages from the restricted subset that that have full-tree matches. The distributions looks largely the same, suggesting that work involving parsetrees can limit attention to the matching-tree subset. However, if an analysis focuses on a specific subset of the tags, then more careful comparison is advised. (For example, x (non-verbal) and ^g (tag-questions) seem to be quite different from this perspective: non-verbal utterances are typically not parsed at all, and tag-questions are often treated as their own dialogue act but merged with the preceding tree when parsed.)
exercise ROOTS, exercise POS, exercise TAGS
SAMPLE Pick a transcript at random and study it a bit, to get a sense for what the data are like. Some things you might informally assess:
META The following code skeleton loops through the transcripts, creating an opportunity to count pieces of meta-data at that level. Complete the code by counting two different pieces of meta-data. Submit both the code and its output as your answer.
Advanced extension: allow the user to supply a Transcript attribute as the argument to the function, and then use that attribute inside the loop, to compile its cont distribution.
ROOTS The following skeletal code loops through the utterances, creating an opportunity to counts utterance-level information.
POSThis question compares heavily edited newspaper text with naturalistic dialogue by looking at the distribution of POS tags in two such resources.
TAGS How are tag questions parsed? Choose one of the following two methods for addressing this:
Home
 This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.